# MIT6.s081-2020 Lab6 Copy-on-Write Fork
虚拟内存提供了一定程度的间接性:内核可以通过将 PTE 标记为无效或只读来拦截内存引用,从而导致页面错误,并且可以通过修改 PTE 来更改地址的含义。计算机系统中有一种说法,即任何系统问题都可以通过一定程度的间接来解决。本实验探讨了另一个示例:copy-on write fork。
# 准备
git fetch
git checkout cow
make clean
2
3
# Implement copy-on write
引言
xv6 中的 fork() 系统调用将所有父进程的用户空间内存复制到子进程中。如果父级很大,则复制可能需要很长时间。更糟糕的是,这项工作经常被大量浪费。例如,子进程中的 fork() 后跟 exec() 将导致子进程丢弃复制的内存,可能不会使用其中的大部分。另一方面,如果父母和孩子都使用一个页面,并且一个或两个都写它,那么确实需要一个副本。因此需要设计copy-on-write (COW) fork(),其目的是延迟为子进程分配和复制物理内存页面,直到实际需要副本(如果有的话)
实现
为了实现上述目标,需要实现的功能如下,即
1、COW fork() 只为子级创建一个页表,用户内存的 PTE 指向父级的物理页面。COW fork() 将 parent 和 child 中的所有用户 PTE 标记为不可写。
2、当任一进程尝试写入这些 COW 页之一时,CPU 将强制发生页错误。内核页面错误处理程序检测到这种情况,为出错进程分配物理内存页面,将原始页面复制到新页面中,并修改出错进程中的相关 PTE 以引用新页面,这次使用PTE 标记为可写。当页面错误处理程序返回时,用户进程将能够写入它的页面副本。
3、COW fork() 使实现用户内存的物理页面的释放变得有点棘手。一个给定的物理页可以被多个进程的页表引用,并且只有在最后一个引用消失时才应该被释放。
根据所给的提示,按照HINT一步步做下去即可。
HINT1:修改 uvmcopy() 以将父级的物理页面映射到子级,而不是分配新页面。清除PTE_W在孩子和父母的 PTE 中。
kernel/vm.c
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
//char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
flags = (flags & ~PTE_W) | PTE_RESERVE;
*pte = (~(*pte ^ ~PTE_W)) | PTE_RESERVE;
//if((mem = kalloc()) == 0)
// goto err;
//memmove(mem, (char*)pa, PGSIZE);
if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
//kfree(mem);
goto err;
}
incref(pa);
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
[注]:对于每个 PTE,有一种方法来记录它是否是 COW 映射可能很有用。为此,您可以使用 RISC-V PTE 中的 RSW(为软件保留)位。
kernel/riscv.h
//...
#define PTE_U (1L << 4) // 1 -> user can access
#define PTE_RESERVE (1L << 8)
2
3
HINT2:修改 usertrap() 以识别页面错误。当 COW 页面发生页面错误时,使用 kalloc() 分配新页面,将旧页面复制到新页面,并在 PTE 中安装新页面PTE_W 放。
kernel/trap.c
void
usertrap(void)
{
//...
}else if(r_scause() == 15) {
uint64 va = r_stval();
pte_t *pte = walk(p->pagetable, va, 0);
if (!(PTE_FLAGS(*pte) & PTE_RESERVE)) {
p->killed = 1;
} else {
va = PGROUNDDOWN(va);
uint64 ka = (uint64)kalloc();
if(ka == 0) {
p->killed = 1;
} else {
uint64 flags = PTE_FLAGS(*pte);
flags = flags & ~PTE_RESERVE;
uint64 pa = walkaddr(p->pagetable, va);
memmove((void*)ka, (void *)pa, PGSIZE);
uvmunmap(p->pagetable, va, 1, 1);
mappages(p->pagetable, va, 1, ka, flags | PTE_W);
}
}
}
//...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
HINT3:确保每个物理页面在对它的最后一个 PTE 引用消失时被释放——但不是在此之前。做到这一点的一个好方法是为每个物理页保留一个“引用计数”,该“引用计数”是指引用该页的用户页表的数量。
我们可以将这些计数保存在固定大小的整数数组中,即使用页面的物理地址除以 4096 来索引数组,并为数组提供等于放置在空闲列表中的任何页面的最高物理地址的元素数量kinit()在 kalloc.c.
为分配页面操作添加一个锁,来实现数据一致性。
kernel/kalloc.c
struct ref_stru {
struct spinlock lock;
uint8 refcount[PHYSTOP / PGSIZE];
} ref;
2
3
4
在kinit中初始化锁:
void
kinit()
{
initlock(&kmem.lock, "kmem");
initlock(&ref.lock, "ref");
freerange(end, (void*)PHYSTOP);
}
2
3
4
5
6
7
初始化的时候需要在freerange把refcount设置为0。
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE) {
ref.refcount[(uint64)p / PGSIZE] = 1;
kfree(p);
}
}
2
3
4
5
6
7
8
9
10
这里设置为1再kfree就变成0了
在kalloc()分配页面时,将页面的引用计数设置为 1。
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r) {
kmem.freelist = r->next;
acquire(&ref.lock);
ref.refcount[(uint64)r / PGSIZE] = 1;
release(&ref.lock);
}
release(&kmem.lock);
//...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
当 fork 导致子共享页面时增加页面的引用计数。
在 uvmcopy的函数结尾添加incref调用来增加页面引用。
void incref(uint64 va) {
acquire(&ref.lock);
ref.refcount[va / PGSIZE]++;
release(&ref.lock);
}
2
3
4
5
kfree()每次任何进程从其页表中删除页面时减少页面的计数,如果其引用计数为零,则应仅将页面放回空闲列表中。
void
kfree(void *pa)
{
//...
// Fill with junk to catch dangling refs.
acquire(&ref.lock);
if(--ref.refcount[(uint64)pa / PGSIZE] > 0) {
release(&ref.lock);
return;
}
release(&ref.lock);
//...
}
2
3
4
5
6
7
8
9
10
11
12
13
HINT4:修改 copyout() 以在遇到拷贝页面时是 COW 页面时使用与页面错误相同的方案。
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
if(dstva > MAXVA - len) return -1;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
pte_t *pte = walk(pagetable, va0, 0);
if(pte == 0) return -1;
if(!(PTE_FLAGS(*pte)&PTE_W)) {
if(!(PTE_FLAGS(*pte)&PTE_RESERVE)) {
return -1;
}
uint64 va = va0;
uint64 ka = (uint64)kalloc();
if(ka == 0) {
return -1;
} else {
uint64 flags = PTE_FLAGS(*pte);
flags = flags & ~PTE_RESERVE;
uint64 pa = walkaddr(pagetable, va);
memmove((void*)ka, (void *)pa, PGSIZE);
uvmunmap(pagetable, va, 1, 1);
mappages(pagetable, va, 1, ka, flags | PTE_W);
}
}
pa0 = walkaddr(pagetable, va0);
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
结果
启动 xv6,运行cowtest ,可以通过测试用例
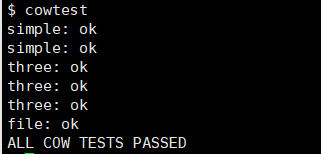
运行usertests,可以通过测试用例。
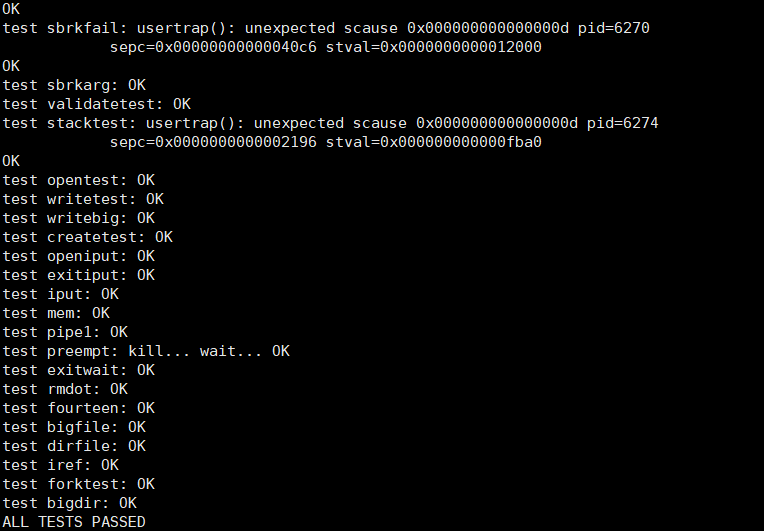
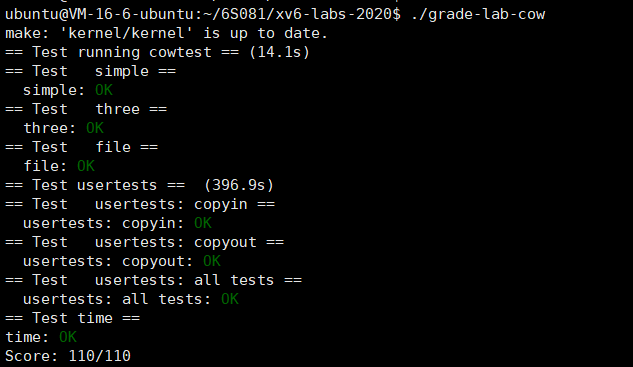
运行grade-lab-cow,可以通过所有的测试用例。
# 总结
总而言之,该实验内容相较于前期做过的内容,较为流畅,但需要把控细节,就引用计数的数组定义中,我们需要添加锁来避免多核下的并发冲突和数据不一致的情况,而本次使用的锁为全局锁,可继续细粒度化,推荐读者可以考虑页面级别的锁。