# MIT6.s081-2020 Lab8 Locks
多核机器上并行性差的一个常见症状是高频率锁的竞争。而常见的提高并行性的方法涉及更改数据结构和锁定策略以减少多线的竞争。本模块将从 xv6 内存分配器和块缓存出发,带你领悟锁的应用。
# 准备
git fetch
git checkout lock
make clean
2
3
# Memory allocator
引言
在内存分配中,常见进程自定义的扩大和缩小地址空间,以达到应用正常运行的目的,然而,重复的调用kalloc和kfree势必将导致多进程对内存资源的竞争,减低系统的效率,过多的上下文切换,势必也将浪费CPU资源。因此,本小节的目的是设计适用于多核状态的内存分配器。传统情况,产生锁竞争的根本原因是kalloc()有一个空闲列表,由一个锁保护。要消除锁争用,必须重新设计内存分配器以避免单个锁和列表,其基本思想是为每个 CPU 维护一个空闲列表,每个列表都有自己的锁。即不同 CPU 上的分配和释放可以并行运行,因为每个 CPU 将在不同的列表上运行
实现
本小节的目标是实现每个 CPU 的空闲列表,并在 CPU 的空闲列表为空时进行窃取,在避免锁无效竞争的同时,提高系统性能。参考所给的HINT,即可顺利实现。
HINT1:使用来自kernel/param.h的常量NCPU,为每一个CPU绑定一个锁对象和内存空间,用于实现多核内存资源的隔离。
kernel/kalloc.c
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
void
kinit()
{
uint64 avg, p;
for(int i = 0; i < NCPU; i++) {
initlock(&kmem[i].lock, "kmem");
}
int idx = 0;
avg = (PHYSTOP - (uint64)end) / NCPU;
for(p = (uint64)end; p <= PHYSTOP; p+=avg) {
actual_freerange((void *)p, p + avg < PHYSTOP?(void *)(p + avg):(void*)PHYSTOP, idx);
idx++;
}
//initlock(&kmem.lock, "kmem");
//freerange(end, (void*)PHYSTOP);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
HINT2:修改freerange和kfree,将所有空闲内存分配给正在运行的 CPU。
功能cpuid返回当前核心编号,但只有在中断关闭时调用它并使用其结果才是安全的。你应该使用 push_off()和pop_off()关闭和打开中断。
void
actual_freerange(void *pa_start, void *pa_end, int i)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
actual_kfree(p, i);
}
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree(p);
}
void
actual_kfree(void *pa, int idx)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem[idx].lock);
r->next = kmem[idx].freelist;
kmem[idx].freelist = r;
release(&kmem[idx].lock);
}
void
kfree(void *pa)
{
//struct run *r;
int idx = 0;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
push_off();
idx = cpuid();
pop_off();
actual_kfree(pa, idx);
// Fill with junk to catch dangling refs.
//memset(pa, 1, PGSIZE);
//r = (struct run*)pa;
//acquire(&kmem.lock);
//r->next = kmem.freelist;
//kmem.freelist = r;
//release(&kmem.lock);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
HINT3:修改kalloc如果当前 cpu 有空闲内存块,就直接返回;没有的话,从其他 cpu 对应的 freelist 中“偷”一块。
void * actual_kalloc(int idx) {
struct run *r;
acquire(&kmem[idx].lock);
r = kmem[idx].freelist;
if(r)
kmem[idx].freelist = r->next;
release(&kmem[idx].lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
void *
kalloc(void)
{
//struct run *r;
int idx = 0;
void * pa;
push_off();
idx = cpuid();
pop_off();
pa = actual_kalloc(idx);
if (pa) return pa;
for(int i = 0; i < NCPU; i++) {
pa = actual_kalloc(i);
if(pa) return pa;
}
return 0;
/*
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
*/
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
结果
启动xv6,运行kalloctest命令,即可通过测试。
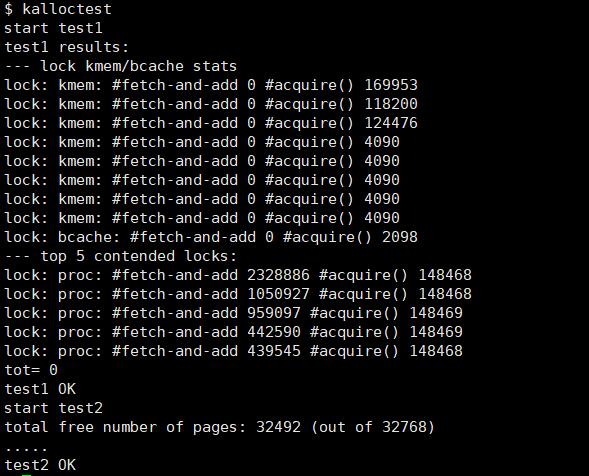
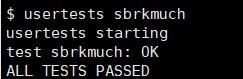
运行usertests sbrkmuch,可以通过测试。
# Buffer cache
引言
由于缓冲区是共享资源,当多个进程密集使用文件系统时,常遇到块缓存区被竞争的现象。减少块缓存中的争用比 kalloc 更棘手,因为 bcache 缓冲区在进程(以及 CPU)之间真正共享。对于 kalloc,可以通过给每个 CPU 自己的分配器来消除大多数争用;这不适用于块缓存。因此,本小节的目的是设计基于哈希表的缓冲区缓存。
实现
本小节的目的是解决 cache 缓存竞争问题,并使用 ticks 的方式代替现有的 LRU 机制。参考所提供的HINT内容,即可实现功能。
HINT1:修改缓冲块的数据结构,使用固定数量的桶而不是动态调整哈希表的大小,来减少散列冲突的可能性。
kernel/param.h
#define MAXPATH 128 // maximum file path name
#define NBUCKET 13 // maximum bucket size
2
kernel/bio.c
struct {
struct spinlock lock;
struct buf buf[NBUF];
struct spinlock buf_lock[NBUCKET];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head[NBUCKET];
} bcache;
2
3
4
5
6
7
8
9
10
11
为 kernel/buf.h 中添加 lastuse 字段,便于使用 LRU 机制:
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
uint lastuse;
};
2
3
4
5
6
7
8
9
10
11
12
13
HINT2:初始化上述锁的定义和缓存链表。
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
for(int i = 0; i < NBUCKET; i++) {
initlock(&bcache.buf_lock[i], "bcache_buf_lock");
}
// Create linked list of buffers
for(int i = 0; i < NBUCKET; i++) {
bcache.head[i].prev = &bcache.head[i];
bcache.head[i].next = &bcache.head[i];
}
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.head[0].next;
b->prev = &bcache.head[0];
initsleeplock(&b->lock, "buffer");
bcache.head[0].next->prev = b;
bcache.head[0].next = b;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
HINT3:修改 brels,bpin和bunpin。当遇到空闲块的时候,直接设置它的使用时间即可。
int hash(int idx) {
return idx % NBUCKET;
}
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int i = hash(b->blockno);
acquire(&bcache.buf_lock[i]);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
/*
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.head.next;
b->prev = &bcache.head;
bcache.head.next->prev = b;
bcache.head.next = b;
*/
b->lastuse = ticks;
}
release(&bcache.buf_lock[i]);
}
void
bpin(struct buf *b) {
int i = hash(b->blockno);
acquire(&bcache.buf_lock[i]);
b->refcnt++;
release(&bcache.buf_lock[i]);
}
void
bunpin(struct buf *b) {
int i = hash(b->blockno);
acquire(&bcache.buf_lock[i]);
b->refcnt--;
release(&bcache.buf_lock[i]);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
HINT4:重新定义bget函数,在保证缓冲命中的同时,避免锁的竞争,保证查找和淘汰缓冲区分配条目的原子性。关键步骤如下:
- 首先还是判断是否命中,如果已经缓存好,皆大欢喜,直接返回;
- 如果没找到,释放锁,按顺序先获取大锁,再获取小锁,避免死锁;这时由于可能释放锁后,又可能会有缓存,因此再遍历一遍;
- 如果还没命中,就去寻找当前 bucket 对应的 LRU 的空闲块,使用 ticks 的方式寻找,如果找到了,就返回;
- 如果还没找到,需要向其他 bucket 中拿内存块。
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b, *b2 = 0;
int idx = hash(blockno),min_ticks = 0;
acquire(&bcache.buf_lock[idx]);
// Is the block already cached?
for(b = bcache.head[idx].next; b != &bcache.head[idx]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.buf_lock[idx]);
acquiresleep(&b->lock);
return b;
}
}
release(&bcache.buf_lock[idx]);
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
acquire(&bcache.lock);
acquire(&bcache.buf_lock[idx]);
for(b = bcache.head[idx].next; b != &bcache.head[idx]; b = b->next){
if(b->dev == dev && b->blockno == blockno) {
b->refcnt++;
release(&bcache.buf_lock[idx]);
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
/**
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
**/
}
for(b = bcache.head[idx].next; b != &bcache.head[idx]; b = b->next){
if(b->refcnt == 0 && (b2 == 0 || b->lastuse < min_ticks)) {
min_ticks = b->lastuse;
b2 = b;
}
}
if(b2) {
b2->dev = dev;
b2->blockno = blockno;
b2->refcnt++;
b2->valid = 0;
release(&bcache.buf_lock[idx]);
release(&bcache.lock);
acquiresleep(&b2->lock);
return b2;
}
for(int j = hash(idx + 1); j != idx; j = hash(j + 1)) {
acquire(&bcache.buf_lock[j]);
for(b = bcache.head[j].next; b != &bcache.head[j]; b = b->next){
if(b->refcnt == 0 && (b2 == 0 || b->lastuse < min_ticks)) {
min_ticks = b->lastuse;
b2 = b;
}
if(b2) {
b2->dev = dev;
b2->blockno = blockno;
b2->refcnt++;
b2->valid = 0;
b2->next->prev = b2->prev;
b2->prev->next = b2->next;
release(&bcache.buf_lock[j]);
b2->next = bcache.head[idx].next;
b2->prev = &bcache.head[idx];
bcache.head[idx].next->prev = b2;
bcache.head[idx].next = b2;
release(&bcache.buf_lock[idx]);
release(&bcache.lock);
acquiresleep(&b2->lock);
return b2;
}
}
release(&bcache.buf_lock[j]);
}
release(&bcache.buf_lock[idx]);
release(&bcache.lock);
panic("bget: no buffers");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
结果
启动xv6,运行bcachetest,可以通过测试。
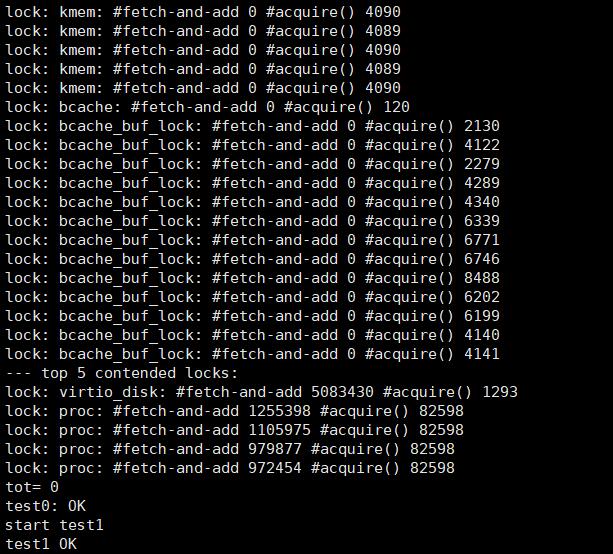
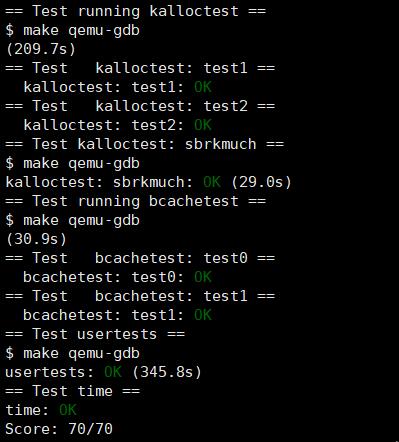
运行make grade,可以通过所有的测试用例。
# 总结
总而言之,本次模块所涉及的内容,十分有意义,令我受益匪浅。
就内存分配器来说,其考虑的是不同CPU下的内存细粒度分配,在保证高效的并行运算能力的同时,避免粗粒度的锁竞争带来的阻塞问题,是常见的并发编程问题。
就缓冲区缓存而言,其所需要设计的内容相较于上者,更加深入。不同于上者的针对CPU处理器的划分方式,其设计需要使用哈希桶的思想,将统一的buf内容划分成相同大小的缓存块,实现相互隔离的同时,需要考虑死锁问题。即在淘汰缓存块过程中,您可能需要持有 bcache 锁和每个桶的锁,来确保避免死锁。笔者采用的方法是双重确认机制来满足淘汰过程的原子性,建议读者可以尝试优化。