# MIT6.824-2020 Lab2A Leader Election and heartbeat
# 前言
本文是本人学习MIT 6.824 Lab 2A的笔记,包含自己一些实现和理解。
Lab 1的说明在 Lab2 Notes (opens new window),需要阅读论文Raft (opens new window)。请以这篇说明和论文为主,以本文为辅。在阅读本文之前,务必先通读这篇说明和论文。若实在无法阅读英文,再姑且直接阅读本文。
本文代码中各种定义和调用非常复杂,很难三言两语说清楚。如果都要一行一行解释,这篇文章篇幅就太太太长了。在本文中呈现代码时,代码中肯定有未解释过的部分,甚至可能占到代码的主要篇幅。请你不要担心,也不要太早地刨根问底,文章中呈现的代码块都只是起到解释说明作用,更多算伪代码,而不是真正运行的代码。
要获得整理好、可直接运行的代码,请看我的GitHub仓库 (opens new window)(最好不要)。
# 思路
# 任务总览
Lab 2A主要代码写在文件src/raft/raft.go。目录src/raft下的其它文件都是为测试服务的,测试主要流程在test_test.go中:首先 raft 启动,在Make 中做初始化,一开始所有的server都是follower,并且每个server会随机分配一个选举超时时间,同时所有的server都有相同的心跳间隔时间。
RequestVote索取选票,AppendEntries实现心跳信号。
和Lab 2A有关的3个测试,难度由小到大,主要如下:
TestInitialElection测试启动后Raft集群是否能够选出一个leader,并检查在网络稳定的情况,也就是不应该发生心跳信号等待超时的情况下,是否能保持原来的leader和term状态不变。
TestReElection测试在上一个测试的基础上,检查发生leader离线情况的行为。先等待集群产生一个leader,然后让这个leader离线,检查集群能否再产生一个leader。若能,令原来的leader上线,检查leader不应该发生变化,因为后来的leader的term大于原来的leader。如果满足要求,令一个leader和一个follower离线,检查此时集群不应该再产生新leader,因为超过半数的服务器离线了。
TestManyElections测试是上一个测试的现实版本。每次随机令2个服务器离线,检查集群状态是否符合要求。如此重复10次。为了确保测试的准确性,我把这个重复次数改成1000,只需要改变量iters就可以。10次通过了是运气好,1000次通过了就是真的对了。
# 实现流程
状态机转化
系统是有限状态机,就是说系统对外只表现出有限的几个状态,状态之间相互转移的中间状态不可见。外界操作使得系统从一个状态转移到另一种状态,转移过程中进行一些处理。外界操作可以相互平行地理解为:
- 系统检测到发生了某件事情,系统应对这件事情改变自己的状态。
- 系统接收到来自外界的指令,按照指令改变自己的状态。
在本次实验中,Raft集群都会或多或少涉及到多种角色的转化,因此,为了保证领袖选举与在线领导心跳控制,最好为每一种角色写一个转换函数:convertToFollower、convertToCandidate、convertToLeader。
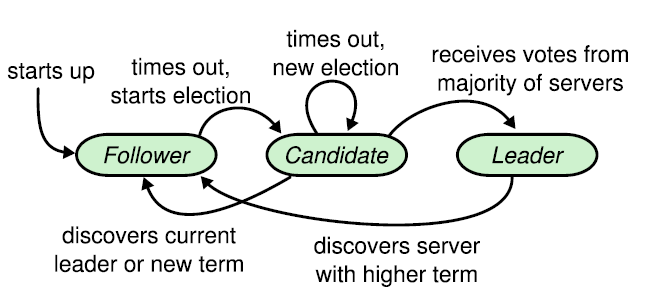
[注]:由于该转换过程涉及到对Raft对象的参数修改,所以需要我们注意死锁发生和重复的锁请求。
无论采用多么非常复杂的加锁机制,都是为了实现一个状态机。与其采用超级烦人的锁、条件变量、或者chan,还不如直接写一个简单的状态机框架。
状态机的主体是一个循环取指令、执行指令的循环,指令就是可能让状态机的状态发生变化的输入。在执行指令的时候给状态上锁。
func (sm *StateMachine) machineLoop() {
for {
trans := <-sm.transCh
sm.rwmu.Lock()
dest := trans.transfer(sm.curState)
if dest != notTransferred {
sm.stateWriter.writeState(dest)
}
sm.rwmu.Unlock()
}
}
2
3
4
5
6
7
8
9
10
11
给chan发射实现了transfer方法的对象,作为指令。
type StateMachine struct {
...
transCh chan SMTransfer
...
}
func (sm *StateMachine) issueTransfer(trans SMTransfer) {
go func() {
sm.transCh <- trans
}()
}
2
3
4
5
6
7
8
9
10
11
异步请求
发送RequestVote应该是异步的,主流程不应该阻塞到所有reply都收到再继续进行。原因有一下两个方面。
- 不需要收到所有选票就可以选出
leader,只需要超过半数。 - RPC放弃发送的时间太长了。
- 最重要的,论文的表述是
election timeout,说明在follower和candidate情况下,发送RequestVote的时机都是计时器到点。
所以,你的发送大概应该长这样。
for i := 0; i < rf.peerCount(); i++ {
if i == rf.me {
// 不发给自己
continue
}
go rf.sendRequestVote(i)
}
2
3
4
5
6
7
AppendEntries也是这个道理。你可以在另一个线程中等待这些线程结束,这样也不会阻塞到主流程。可以像这样。
// On conversion to candidate, start election
// Increment currentTerm
currentTerm++
// Vote for self
votedFor = trans.machine.raft.me
// Reset election timer
electionTimer.setElectionWait()
electionTimer.start()
// Send RequestVote RPCs to all other servers
go trans.machine.raft.doElect()
// 不阻塞的返回
return StartElectionState
2
3
4
5
6
7
8
9
10
11
12
13
随机超时
在选举领袖中,为了防止瓜分选票的情况发生,需要随机设置不同的超时时间,论文建议是150-300ms ,所以建议写个函数,用时间戳做随机种子,每次生成不同的超时时间。
在心跳间隔中,要求心跳不超过10次/s,也就是不小于100ms/次,而心跳时间间隔应该小于选举超时时间,因此设置为100到150ms之间。
事件触发
根据论文解析,我们需要长时间运行的gorutinue (可以简单理解为死循环)来处理事件和统计选举超时。此处可以使用管道来协调。在开始选举时,当某一台server 的选举超时计时先倒数完,这台server按照规则,先给变成candidate,term加一,给自己投票,重置选举超时计时器,然后让其他server投票。只要超过半数,那么就当选leader,开始给其余节点发心跳。
# 常见问题
- 没有理解清楚算法流程不要硬上,多看看论文,反复琢磨总是能懂的!
- 不要先追求效率或优雅,很多错误就是这么来的,先追求正确!
- 多线程代码不要用断点调试了,可以尝试在终端
print一些信息,像这样: