# 基于etcd的源码分析
# 一、etcd概述
# 1.1 etcd是什么
ectd是CoreOS公司发起的一个开源项目,是用于共享配置和服务发现的分布式,一致性的KV存储系统,它的目标是提供了一种可靠的方法来存储分布式系统或机器集群需要访问的数据。具有以下特点:
(1) 简单:安装配置简单,且提供HTTP API进行交互,使用也简单;
(2) 存储:将数据存储在分层组织的目录中,如同在标准文件系统中;
(3) Watch机制:Watch 指定的键、前缀目录的更改,监测特定的键或目录的更改时机,并能对值的更改做出相应的反应;
(4) 安全:支持 SSL 证书验证;
(5) 快速:按照官网给出的数据, 在2CPU,1.8G内存,SSD磁盘这样的配置下,单节点的写性能可以达到16K QPS, 而先写后读也能达到12K QPS;
(6) 一致可靠:基于 Raft 共识算法,实现分布式系统内部数据存储、服务调用的一致性和高可用性;
(7) Revision 机制:每个 Key 带有一个 Revision 号,每进行一次事务便加一,因此它是全局唯一的,如初始值为 0,进行一次 Put 操作,Key 的 Revision 变为 1,同样的操作,再进行一次,Revision 变为 2;换成 Key1 进行 Put 操作,Revision 将变为 3。这种机制有一个作用,即通过 Revision 的大小就可知道写操作的顺序,这对于实现公平锁,队列十分有益;
(8) Lease 机制:即租约机制(TTL,Time To Live),Etcd 可以为存储的 Key-Value 对设置租约,当租约到期,Key-Value 将失效删除;同时也支持续约,通过客户端可以在租约到期之前续约,以避免 Key-Value 对过期失效;此外,还支持解约,一旦解约,与该租约绑定的 Key-Value 将失效删除;

# 1.2 应用场景
etcd 在稳定性、可靠性和可伸缩性上表现极佳,同时也为云原生应用系统提供了协调机制。etcd 经常用于服务注册与发现的场景,此外还有键值对存储、消息发布与订阅、分布式锁等场景。
# 1.2.1 服务发现
服务发现要解决的也是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听 udp 或 tcp 端口,并且通过名字就可以查找和连接。要解决服务发现的问题,需要有下面三大支柱,缺一不可。
(1) 一个强一致性、高可用的服务存储目录。基于 Raft 算法的etcd天生就是这样一个强一致性高可用的服务存储目录;
(2) 一种注册服务和监控服务健康状态的机制。用户可以在etcd中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。
(3) 一种查找和连接服务的机制。通过在etcd指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个 Proxy 模式的 etcd,这样就可以确保能访问etcd集群的服务都能互相连接。
# 1.2.2 消息发布与订阅
在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。通过这种方式可以做到分布式系统配置的集中式管理与动态更新。
(1) 应用中用到的一些配置信息放到etcd上进行集中管理。应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个 Watcher 并等待,以后每次配置有更新的时候,etcd 都会实时通知订阅者,以此达到获取最新配置信息的目的;
(2) 分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在etcd中,供各个客户端订阅使用。etcd租约机制可以确保机器状态是实时更新的;
(3) 分布式日志收集系统。这个系统的核心工作是收集分布在不同机器的日志。收集器通常是按照应用(或主题)来分配收集任务单元,因此可以在etcd上创建一个以应用(主题)命名的目录 P,并将这个应用(主题相关)的所有机器 ip,以子目录的形式存储到目录 P 上,然后设置一个etcd递归的 Watcher,递归式的监控应用(主题)目录下所有信息的变动,即这样就实现了机器 IP(消息)变动的时候,能够实时通知到收集器调整任务分配;
(4) 系统中信息需要动态自动获取与人工干预修改信息请求内容的情况。通常是暴露出接口,例如 JMX 接口,来获取一些运行时的信息。引入etcd之后,就不用自己实现一套方案了,只要将这些信息存放到指定的etcd目录中即可,etcd 的这些目录就可以通过 HTTP 的接口在外部访问。
# 1.2.3 服务均衡
分布式系统中,为了保证服务的高可用以及数据的一致性,通常都会把数据和服务部署多份,以此达到对等服务,即使其中的某一个服务失效了,也不影响使用。由此带来的坏处是数据写入性能下降,而好处则是数据访问时的负载均衡。因为每个对等服务节点上都存有完整的数据,所以用户的访问流量就可以分流到不同的机器上。
(1) etcd本身分布式架构存储的信息访问支持负载均衡。etcd 集群化以后,每个etcd的核心节点都可以处理用户的请求。
(2) 利用etcd维护一个负载均衡节点表。etcd 可以监控一个集群中多个节点的状态,当有一个请求发过来后,可以轮询式的把请求转发给存活着的多个状态。
# 1.2.4 分布式通知与协调
分布式通知与协调与前面提到的消息发布和订阅有些相似,都用到了etcd中的 Watcher 机制,通过注册与异步通知机制,实现分布式环境下不同系统之间的通知与协调,从而对数据变更做到实时处理。
实现方式通常是这样:不同系统都在etcd上对同一个目录进行注册,同时设置 Watcher 观测该目录的变化,当某个系统更新了etcd的目录,那么设置了 Watcher 的系统就会收到通知,并作出相应处理。
(1) 通过etcd进行低耦合的心跳检测。检测系统和被检测系统通过etcd上某个目录关联而非直接关联起来,这样可以大大减少系统的耦合性。
(2) 通过etcd完成系统调度。某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改了etcd上某些目录节点的状态,而etcd就把这些变化通知给注册了 Watcher 的推送系统客户端,推送系统再作出相应的推送任务。
(3) 通过etcd完成工作汇报。大部分类似的任务分发系统,子任务启动后,到etcd来注册一个临时工作目录,并且定时将自己的进度进行汇报,这样任务管理者就能够实时知道任务进度。
# 1.2.5 分布式锁
因为 etcd 使用 Raft 算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
(1) 保持独占即所有获取锁的用户最终只有一个可以得到。etcd 为此提供了一套实现分布式锁原子操作 CAS(CompareAndSwap)的 API。通过设置prevExist值,可以保证在多个节点同时去创建某个目录时,只有一个成功。而创建成功的用户就可以认为是获得了锁。
(2) 控制时序,即所有想要获得锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,同时决定了执行顺序。etcd 为此也提供了一套 API(自动创建有序键),对一个目录建值时指定为POST动作,这样 etcd 会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用 API 按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
# 1.2.6 分布式队列
分布式队列的常规用法与分布式锁的控制时序用法类似,即创建一个先进先出的队列,保证顺序。另一种比较有意思的实现是在保证队列达到某个条件时再统一按顺序执行。这种方法的实现可以在 /queue 这个目录中另外建立一个 /queue/condition 节点。
(1) condition 可以表示队列大小。比如一个大的任务需要很多小任务就绪的情况下才能执行,每次有一个小任务就绪,就给这个 condition 数字加 1,直到达到大任务规定的数字,再开始执行队列里的一系列小任务,最终执行大任务。
(2) condition 可以表示某个任务在不在队列。这个任务可以是所有排序任务的首个执行程序,也可以是拓扑结构中没有依赖的点。通常,必须执行这些任务后才能执行队列中的其他任务。
(3) condition 还可以表示其它的一类开始执行任务的通知。可以由控制程序指定,当 condition 出现变化时,开始执行队列任务。
# 1.2.7 集群监控与Leader竞选
通过 etcd 来进行监控实现起来非常简单并且实时性强。例如,前面几个场景已经提到 Watcher 机制,当某个节点消失或有变动时,Watcher 会第一时间发现并告知用户。此外,节点可以设置TTL key,比如每隔 30s 发送一次心跳使代表该机器存活的节点继续存在,否则节点消失。这样就可以第一时间检测到各节点的健康状态,以完成集群的监控要求。
另外,使用分布式锁,可以完成 Leader 竞选。这种场景通常是一些长时间 CPU 计算或者使用 IO 操作的机器,只需要竞选出的 Leader 计算或处理一次,就可以把结果复制给其他的 Follower。从而避免重复劳动,节省计算资源。
这个的经典场景是搜索系统中建立全量索引。如果每个机器都进行一遍索引的建立,不但耗时而且建立索引的一致性不能保证。通过在 etcd 的 CAS 机制同时创建一个节点,创建成功的机器作为 Leader,进行索引计算,然后把计算结果分发到其它节点。
# 1.3 常用术语
为了有效提高读者阅读的效率,本小节将总结后续常出现的专用术语,先混个眼熟,后续具体实现过程会继续深入。
| 术语 | 描述 | 备注 |
|---|---|---|
| Raft | Raft算法,etcd实现一致性的核心 | ectd-raft 模型 |
| Follower | Raft中的从属节点 | 竞争Leader失败 |
| Leader | Raft中的领导节点,处理数据提交 | Leader协调集群 |
| Candidate | 候选节点 | 当Follower接收Leader节点的消息超时会转变为Candidate |
| Node | Raft状态机的实例 | Raft中涉及多个节点 |
| Member | etcd实例,管理对应Node节点 | 可处理客户端请求 |
| Peer | 同一个集群中的另一个Member | 其他成员 |
| Cluster | etcd集群 | 拥有多个ectd Member |
| Lease | 租期 | 关键设置的租期,过期删除 |
| Watch | 监测机制 | 监控键值对的变化 |
| Term | 任期 | 某个节点成为Leader, 到下一次竞选的时间 |
| WAL | 预写式日志 | 持久化存储的日志格式 |
| MVCC | 多版本并发控制 | 事务隔离的手段 |
| revision | MVCC中的版本 | 每一次key-value操作都会有revision |
| keyIndex | Key的生命周期 | 记录一个key的生命周期中所涉及过的版本 |
| Client | 客户端 | 向etcd发起请求的客户端 |
# 二、etcd组成模型
# 2.1 服务器状态
严格来说,ectd节点有三种角色:Leader、Flower、Candidate。Leader:复制处理所有与客户端的交互和数据处理,协调follower,只有一个;Follower:听从Leader差遣;Candidate:当没有Leader的时候,所有服务器可以竞选Leader,向其他服务器拉票;
节点角色会在以上三种角色中进行切换。
# 2.2 核心架构
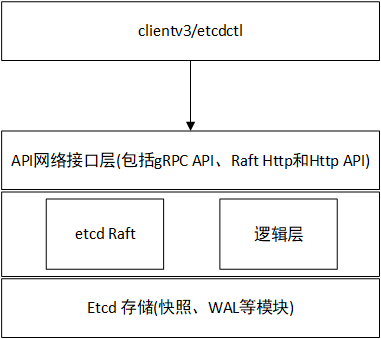
etcd 整体架构图如所示。其中,etcd 有 etcd Server、gRPC Server、存储相关的 MVCC 、Snapshot、WAL,以及 Raft 模块。通过分层的方式,我们可以依次将其分为客户端层、API接口层、Raft层、逻辑层、数据存储层。
(1) 客户端层
客户端层包括clientv3 和 etcdctl 等客户端。用户通过命令行或者客户端调用提供了 RESTful 风格的 API,降低了 etcd 的使用复杂度。
除此之外,客户端层的负载均衡和节点间故障转移等特性也提升了 etcd 服务端的高可用性。
(2) API接口层
API 接口层提供了客户端访问服务端的通信协议和接口定义,以及服务端节点之间相互通信的协议。etcd 有V3和V2两个版本:
etcd V3使用 gRPC 作为消息传输协议;
etcd V2默认使用 HTTP/1.x 协议。
对于不支持 gRPC 的客户端语言,etcd 提供 JSON 的 grpc-gateway 。通过 grpc-gateway 提供 RESTful代理,转换 HTTP/JSON 请求为 gRPC 的 Protocol Buffer 格式的消息。
然而,值得注意的是,etcd V2 和 V3 是在底层使用同一套 Raft 算法的两个独立应用,但相互之间实现原理和使用方法上差别很大,接口不一样、存储不一样,两个版本的数据互相隔离。
(1) Raft层
Raft 层作为etcd关键的基础模块,主要负责 Leader 选举和日志复制等功能,除了与本节点的 etcd Server 通信之外,还与集群中的其他 etcd 节点进行交互,实现分布式一致性数据同步的关键工作。
(2) 逻辑层
etcd 的业务逻辑层,包括鉴权、租约、KVServer、MVCC 和 Compactor 压缩等核心功能特性。
(3) 数据存储层
数据存储层中主要实现了快照、预写式日志 WAL。
# 2.3 读写总体概述
总览etcd各个模块间的交互,总体上的请求流程从上至下依次为客户端 → API 接口层 → etcd Server → etcd raft 算法库。
# 2.3.1 读请求执行流程
etcd 中一个读请求的具体执行流程如下:
首先,客户端会创建一个 clientv3 库对象,通过负载均衡算法选择一个 etcd 节点,使用 KVServer 模块的 API 来访问 etcd server;
然后,client 发送Range RPC请求到了server后就进入了KVServer模块;
server 收到client的Range RPC请求后,根据ServiceName和RPC Method将请求转发到对应的handler实现;
handler首先会将上面描述的一系列拦截器串联成一个拦截器再执行,在拦截器逻辑中,通过调用KVServer模块的Range接口获取数据。
在etcd读请求的核心,需要经过线性读 ReadIndex 模块、MVCC(包含 treeIndex 和 BlotDB)模块。
其中,线性读是相对串行读来讲的概念。集群模式下会有多个 etcd 节点,不同节点之间可能存在一致性问题,串行读直接返回状态数据,不需要与集群中其他节点交互。这种方式速度快,开销小,但是会存在数据不一致的情况。线性读则需要集群成员之间达成共识,存在开销,响应速度相对慢。但是能够保证数据的一致性,etcd 默认读模式是线性读。
# 2.3.2 写请求执行流程
etcd 一个写请求的完整执行流程,主要包括 Quota模块、KVServer模块、WAL模块、Apply模块和MVCC模块。
首先,client端通过负载均衡算法选择一个etcd节点,发起 gRPC 调用;
然后,etcd节点收到请求后经过gRPC拦截器、Quota 模块后,进入 KVServer 模块,Quota 模块用于校验 etcd db 文件大小是否超过了配额;
KVServer模块向 Raft 模块提交一个提案,提案内容为“xxx”;
随后此提案通过 Raft HTTP 网络模块转发、经过集群多数节点持久化后,状态会变成已提交;
Etcd server 从 Raft 模块获取已提交的日志条目,传递给 Apply 模块;
Apply 模块通过 MVCC 模块执行提案内容,更新状态机。
与读流程不一样的是写流程还涉及 Quota、WAL、Apply 三个模块。此外,etcd 的 crash-safe 及幂等性也正是基于 WAL 和 Apply 流程的 consistent index 等实现的。
# 三、源码分析
# 3.1 源码结构及功能
相较于以往的版本有所不同,etcd 项目(从 3.5 版开始)被组织成多个 golang 模块。具体目录结构如下:
├─api 定义 etcd 客户端和服务器之间通信协议的 API 定义
├─CHANGELOG
├─client Go语言客户端SDK
│ ├─pkg
│ ├─v2
│ └─v3
├─contrib raftexample实现
├─Documentation
├─etcdctl 命令行客户端实现,用于访问和管理 etcd 的命令行工具
├─etcdutl 命令行管理实用程序,可直接操作etcd数据文件
├─hack 为开发人员提供的扩展
├─pkg ectd使用的工具集合
├─raft raft算法模块。分布式共识协议的实现
├─scripts 脚本、测试等相关内容
├─security 脚本、测试等相关内容
├─server etcd server模块,etcd 内部实现
├─tests 一个包含所有 etcd 集成测试的模块
└─tools 脚本、测试等相关内容
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 3.2 客户端设计
作为etcd的基础模块,etcd 客户端包括 client v2 和 v3 两个大版本 API 客户端库,提供了简洁易用的 API,同时支持负载均衡、节点间故障自动转移,可极大降低业务使用 etcd 复杂度,提升开发效率、服务可用性。接下来,我们将以client v3版本为例,介绍客户端相关设计内容。
# 3.2.1 Client对象
要访问etcd第一件事就是创建client对象,而client对象需要传入一个Config配置,具体初始化方法如下:
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"localhost:2379"},
DialTimeout: 5 * time.Second, }
)
2
3
4
这里传了2个选项:
- Endpoints:etcd的多个节点服务地址,因为我是单点测试,所以只传1个;
- DialTimeout:创建client的首次连接超时,这里传了5秒,如果5秒都没有连接成功就会返回err;值得注意的是,一旦client创建成功,我们就不用再关心后续底层连接的状态了,client内部会重连。
当然,如果上述err != nil,那么一般情况下我们可以选择重试几次,或者退出程序。
这里我们重点了解一下Client 定义:
client/client.go:
// Client provides and manages an etcd v3 client session.
type Client struct {
Cluster
KV
Lease
Watcher
Auth
Maintenance
// Username is a user name for authentication.
Username string
// Password is a password for authentication.
Password string
// contains filtered or unexported fields
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这里显示的都是可导出的模块结构字段,代表了客户端能够使用的几大核心模块,具体功能如下:
(1) Cluster:向集群里增加 etcd 服务端节点之类,属于管理员操作;
(2) KV:实际操作中主要使用的功能,即操作 K-V对象。实际上client.KV是一个interface,提供了关于k-v操作的所有方法,在使用过程中,常需要使用装饰者模式包装后的KV对象,对象中内置错误重试机制。具体代码如下:
client/kv.go:
type KV interface {
Put(…) (*PutResponse, error) // 存储键值对
Get(…) (*GetResponse, error) // 检索键值对
Delete(…) (*DeleteResponse, error) // 删除键值对
Compact(…) (*CompactResponse, error) // 压缩给定版本之前的 KV 历史
Do(…) (OpResponse, error) // 指定某种没有事务的操作
Txn(…) Txn // Txn 创建一个事务
}
client/kv.go:
func NewKV(c *Client) KV {
api := &kv{remote: RetryKVClient(c)}
if c != nil {
api.callOpts = c.callOpts
}
return api
}
client/kv.go:
// 需要注意的是此处具体构建装饰的对象是KVClient
// KVClient 对象是实际是KVService的客户端API。
type kv struct {
remote pb.KVClient
callOpts []grpc.CallOption
}
client/retry.go:
// RetryKVClient implements a KVClient.
func RetryKVClient(c *Client) pb.KVClient {
return &retryKVClient{
kc: pb.NewKVClient(c.conn),
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
(3) Lease:租约相关操作,比如申请一个 TTL=10 秒的租约。和获取KV对象一样,通过下面代码获取它:
type Lease interface {
Grant(…) (*LeaseGrantResponse, error) 分配租约
Revoke(…) (*LeaseRevokeResponse, error) 释放租约
TimeToLive(…) (*LeaseTimeToLiveResponse, error) 获取剩余TTL时间
Leases(…) (*LeaseLeasesResponse, error) 列举所有etcd中的租约
KeepAlive(…) (<-chan *LeaseKeepAliveResponse, error) 自动定时的续约某个租约
KeepAliveOnce(…) (*LeaseKeepAliveResponse, error) 为某个租约续约一次
Close() error 关闭客户端建立的所有租约
}
func NewLease(c *Client) Lease {
return NewLeaseFromLeaseClient(RetryLeaseClient(c), c, c.cfg.DialTimeout+time.Second)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
(4) Watcher:观察订阅,从而监听最新的数据变化;
(5) Auth:管理 etcd 的用户和权限,属于管理员操作;
(6) Maintenance:维护 etcd,比如主动迁移 etcd 的 leader 节点,属于管理员操作。
# 3.2.2 gRPC服务
etcd client v3库针对gRPC服务的实现采用的负载均衡算法为 Round-robin。即针对每一个请求,Round-robin 算法通过轮询的方式依次从 endpoint 列表中选择一个 endpoint 访问(长连接),使 etcd server 负载尽量均衡。
client/client.go func newClient:
conn, err := client.dialWithBalancer()
client/client.go 建立了到etcd的服务端链接
func (c *Client) dialWithBalancer(dopts ...grpc.DialOption) (*grpc.ClientConn, error) {
creds := c.credentialsForEndpoint(c.Endpoints()[0])
opts := append(dopts, grpc.WithResolvers(c.resolver))
return c.dial(creds, opts...)
}
client/client.go
func (c *Client) dial(creds grpccredentials.TransportCredentials, dopts ...grpc.DialOption) (*grpc.ClientConn, error) {
// 首先,ETCD通过这行代码,向GRPC框架加入了一些自己的
// 配置,比如:KeepAlive特性(配置里提到的配置项)、
// TLS证书配置、还有最重要的重试策略。
opts, err := c.dialSetupOpts(creds, dopts...)
...
// context 的一段经典样例代码
// 问:如果我同时把非零的DialTimeout和带超时的 context 传给客户端,
// 到底以哪个超时为准?
// 答:这里新建了子context(dctx),父context和DialTimeout
// 哪个先到deadline,就以哪个为准。
dctx := c.ctx
if c.cfg.DialTimeout > 0 {
var cancel context.CancelFunc
// 同时包含父context和DialTimeout
// 哪个先倒时间就以哪个为准。
dctx, cancel = context.WithTimeout(c.ctx, c.cfg.DialTimeout)
defer cancel()
}
// 最终调用grpc.DialContext()建立连接
conn, err := grpc.DialContext(dctx, target, opts...)
...
return conn, nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 3.2.3 重试策略分析
自动重试是ETCD能提供高可用特性的重要保证,此处需要注意的是:自动重试不会在etcd集群的同一节点上进行,这跟我们平常做的重试不同,就如前面提到的 etcd是通过grpc框架提供对集群访问的负载均衡策略的,所以此时client端会轮询的重试集群的每个节点,此外,自动重试只会重试一些特定的错误。
//client/client.go 这段代码在dialWithBalancer->dial->dialSetupOpts中
// dialSetupOpts gives the dial opts prior to any authentication.
func (c *Client) dialSetupOpts(creds grpccredentials.TransportCredentials, dopts ...grpc.DialOption) (opts []grpc.DialOption, err error) {
if c.cfg.DialKeepAliveTime > 0 {
params := keepalive.ClientParameters{
Time: c.cfg.DialKeepAliveTime,
Timeout: c.cfg.DialKeepAliveTimeout,
PermitWithoutStream: c.cfg.PermitWithoutStream,
}
opts = append(opts, grpc.WithKeepaliveParams(params))
}
opts = append(opts, dopts...)
if creds != nil {
opts = append(opts, grpc.WithTransportCredentials(creds))
} else {
opts = append(opts, grpc.WithInsecure())
}
// Interceptor retry and backoff.
// TODO: Replace all of clientv3/retry.go with RetryPolicy:
// https://github.com/grpc/grpc-proto/blob/cdd9ed5c3d3f87aef62f373b93361cf7bddc620d/grpc/service_config/service_config.proto#L130
rrBackoff := withBackoff(c.roundRobinQuorumBackoff(defaultBackoffWaitBetween, defaultBackoffJitterFraction))
opts = append(opts,
// Disable stream retry by default since go-grpc-middleware/retry does not support client streams.
// Streams that are safe to retry are enabled individually.
grpc.WithStreamInterceptor(c.streamClientInterceptor(withMax(0), rrBackoff)),
grpc.WithUnaryInterceptor(c.unaryClientInterceptor(withMax(defaultUnaryMaxRetries), rrBackoff)),
)
return opts, nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
看以上的代码,要自动重试只需两步:
(1) 创建backoff函数,也就是计算重试等待时间的函数。
(2) 通过WithXXXInterceptor(),注册重试拦截器,这样每次GRPC有请求都会回调该拦截器。
值得注意的是,这里我们看到Stream的重试拦截器的注册,其最大重试次数设置为了0(withMax()),也就是不重试,这其实是故意为之,因为Client端的Stream重试不被支持,即Client端需要重试Stream,需要自己做单独处理,不能通过拦截器。
首先看看如何计算等待时间:
//client/client.go
// waitBetween 重试间隔时长,jitterFraction 随机抖动率,
// 比如:默认重试间隔为25ms,抖动率:0.1,
// 那么实际重试间隔就在 25土2.5ms 之间,attempt 实际重试了多少次
// roundRobinQuorumBackoff retries against quorum between each backoff.
// This is intended for use with a round robin load balancer.
func (c *Client) roundRobinQuorumBackoff(waitBetween time.Duration, jitterFraction float64) backoffFunc {
return func(attempt uint) time.Duration {
// after each round robin across quorum, backoff for our wait between duration
n := uint(len(c.Endpoints()))
quorum := (n/2 + 1)
if attempt%quorum == 0 {
c.lg.Debug("backoff", zap.Uint("attempt", attempt), zap.Uint("quorum", quorum), zap.Duration("waitBetween", waitBetween), zap.Float64("jitterFraction", jitterFraction))
return jitterUp(waitBetween, jitterFraction)
}
c.lg.Debug("backoff skipped", zap.Uint("attempt", attempt), zap.Uint("quorum", quorum))
return 0
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
可以发现的是roundRobinQuorumBackoff返回了一个闭包,内部是重试间隔时长计算逻辑,这个逻辑说来也简单:
(1) 若重试次数已经达到集群的法定人数(quorum),则真正的计算间隔时长,间隔时长到期后,才进行重试。
(2) 否则,直接返回0,也就是马上重试。
就如前面所提到的,负载均衡策略是轮询,而这个重试逻辑一定要配合负载均衡是轮询策略才能达到的效果:假如你访问集群中的一台节点失败,可能是那台节点出问题了,但如果整个集群是好的,这时候马上重试,轮询到下台节点就行。
但是,如果重试多次,集群大多数节点(法定人数)都失败了,那应该是集群出问题了,这时候就需要计算间隔时间,等会儿再重试看看问题能不能解决。
这里也可以看到etcd的Client端,考虑的细节问题是非常多的,一个简单的重试时间计算,也能进行逻辑上的小小优化。
重试拦截器相关代码实现如下:
func (c *Client) unaryClientInterceptor(optFuncs ...retryOption) grpc.UnaryClientInterceptor {
...
// 如果最大重试次数设置为0,那就不重试。
if callOpts.max == 0 {
return invoker(ctx, method, req, reply, cc, grpcOpts...)
}
var lastErr error
// 开始重试计数
for attempt := uint(0); attempt < callOpts.max; attempt++ {
// 计算重试间隔时间,并阻塞代码,等待
// 这里最终会调用到 roundRobinQuorumBackoff 来计算时间
if err := waitRetryBackoff(ctx, attempt, callOpts); err != nil {
return err
}
// 再次重新执行GRPC请求
lastErr = invoker(ctx, method, req, reply, cc, grpcOpts...)
if lastErr == nil {
// 重试成功,退出
return nil
}
// 这段代码分析了两种情况
// 1. 服务端返回了 Context Error(超时、被取消),直接重试
// 2. 客户端的 Context 也出现了Error
if isContextError(lastErr) {
if ctx.Err() != nil {
// 客户端本身的ctx也报错了,不重试了,退出。
return lastErr
}
// 服务端返回,直接重试
continue
}
if callOpts.retryAuth && rpctypes.Error(lastErr) == rpctypes.ErrInvalidAuthToken {
// 是AuthToken不正确,重新获取Token
gterr := c.getToken(ctx)
...
continue
}
// 只有在特定错误才重试(code.Unavailable)
// 否则返回Err,不重试。
if !isSafeRetry(c.lg, lastErr, callOpts) {
return lastErr
}
}
return lastErr
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 3.3 API 接口层设计
# 3.3.1 通信方式概述
时至今日,etcd通信方式经过了两次较为明显的版本更替。早期的etcd通信版本是v2,通过HTTP+JSON暴露外部API,由于经常需要服务感知节点配置变动或者监听推送,客户端和服务端需要频繁通信,早期的v2采用HTTP1.1的长连接来维持,经过如此通信效率依然不高。
因此,etcd v3版本引进了grpc+protobuf的通信方式(基于HTTP/2.0),其优势在于:
(1) 采用二进制压缩传输,序列/反序列化更加高效
(2) 基于HTTP2.0的服务端主动推送特性,对事件多路复用做了优化
(3) Watch功能使用grpc的stream流进行感知,同一个客户端和服务端采用单一连接,替代v2的HTTP长轮询检测,直接减少连接数和内存开销
etcd v3版本为了向上兼容v2 API版本,提供了grpc网关来支持原HTTP JSON接口支持。考虑到etcd v3版本提供了丰富的功能优化,后续的代码分析将以v3版本为主体进行介绍。
# 3.3.2 etcd v3
etcd v3在设计之初的通信基于 gRPC,proto 文件是定义服务端和客户端通讯接口的标准。即客户端该传什么样的参数,服务端该返回什么样子的参数,客户端该怎么调用,是阻塞还是非阻塞,是同步还是异步。
在进行核心API接口层设计的学习之前,gRPC 推荐使用 proto3,我们需要对 proto3 的基本语法有初步的了解。proto3 是原有 Protocol Buffer 2(被称为 proto2)的升级版本,删除了一部分特性,优化了对移动设备的支持,另外增加了对android和ios的支持,使得 gRPC 可以顺利的在移动设备上使用。
一个 .proto 文件的编译之后,编译器会为你选择的语言生成代码。你在文件中描述的消息类型,包括获取和设置字段的值,序列化你的消息到一个输出流,以及从一个输入流中转换出你的消息。
(1) 对于 C++,编译器会为每个 .proto 文件生成一个 .h 和一个 .cc 的文件,为每一个给出的消息类型生成一个类。
(2) 对于 Java,编译器会生成一个java文件,其中为每一个消息类型生成一个类,还有特殊的用来创建这些消息类实例的Builder类,
(3) Python编译器生成一个模块,其中为每一个消息类型生成一个静态的描述器,在运行时,和一个 metaclass 一起使用来创建必要的 Python 数据访问类。
(4) 对于 Go,编译器为每个消息类型生成一个 .pb.go 文件。
# 3.3.3 gRPC服务
在proto文件(api/etcdserverpb/rpc.proto)中,etcd 的 RPC 接口定义根据功能分类到服务中。
其中,处理 etcd 键值的重要服务包括:
KV Service:创建、更新、获取和删除键值对;
Watch Service:监视键的更改;
Lease Service:实现键值对过期,客户端用来续租、保持心跳;
Lock Service:etcd 提供分布式共享锁的支持;
Election Service:暴露客户端选举机制;
这些服务统一在api/etcdserverpb/*.proto文件中进行了相应的声明。例如,这里是Range RPC描述:
service KV {
// Range gets the keys in the range from the key-value store.
rpc Range(RangeRequest) returns (RangeResponse) {
option (google.api.http) = {
post: "/v3/kv/range"
body: "*"
};
}
….
}
2
3
4
5
6
7
8
9
10
11
此外,etcd API 的所有响应都有一个附加的响应标头,其中包括响应的群集元数据:
message ResponseHeader {
uint64 cluster_id = 1; // 产生响应的集群的 ID
uint64 member_id = 2; // 产生响应的成员的 ID
int64 revision = 3; // 产生响应时键值存储的修订版本号
uint64 raft_term = 4; //产生响应时,成员的 Raft 称谓
}
2
3
4
5
6
7
这些元数据在实际使用过程中,都提供了如下功能:
(1) 应用服务可以通过 Cluster_ID 和 Member_ID 字段来确保,当前与之通信的正是预期的那个集群或者成员;
(2) 应用服务可以使用修订号字段来知悉当前键值存储库最新的修订号。当应用程序指定历史修订版以进行时程查询并希望在请求时知道最新修订版时,此功能特别有用;
(3) 应用服务可以使用 Raft_Term 来检测集群何时完成一个新的 leader 选举;
# 3.4 服务端设计
作为etcd的最核心模块,etcd 服务端模块定义了主要的接口以及数据交互格式,并解决以下问题:接收客户端的请求并对节点进行分发;感知集群成员变动,对成员通知;同步或者启动恢复快照等。
Etcd 服务端主要由几大组件构成,各部分介绍如下:
(1) EtcdServer[etcdserver/server.go] 主进程,直接或者间接包含了raftNode、WAL、snapshotter 等多个核心组件,可以理解为一个容器。
(2) raftNode[etcdserver/raft.go] 对内部 RAFT 协议实现的封装,暴露简单的接口,用来保证写事务的集群一致性。
接下来,将以EtcdServer为核心进行源码分析,有关具体的Raft协议内容,将会在下一节具体给出。
# 3.4.1 Server对象
ETCD 服务器是通过 EtcdServer 结构抽象,对应了 etcdserver/server.go 中的代码,包含属性 r raftNode,代表 RAFT 集群中的一个节点,启动入口在 etcdmain/main.go 文件中。具体代码如下:
// etcdmain/main.go
func Main(args []string) {
checkSupportArch()
if len(args) > 1 {
cmd := args[1]
switch cmd {
case "gateway", "grpc-proxy":
if err := rootCmd.Execute(); err != nil {
fmt.Fprint(os.Stderr, err)
os.Exit(1)
}
return
}
}
startEtcdOrProxyV2(args)
}
// embed/etcd.go 此处列出部分字段
// Etcd contains a running etcd server and its listeners.
type Etcd struct {
Peers []*peerListener
Clients []net.Listener
// a map of contexts for the servers that serves client requests.
sctxs map[string]*serveCtx
metricsListeners []net.Listener
…
// 核心对象服务器接口的生产实现
Server *etcdserver.EtcdServer
…
}
// 启动调用链过程(考虑到服务器的分析的复杂性,此处通过函数分支的方式进行介绍)
main() etcdmain/main.go
|-checkSupportArch()
|-startEtcdOrProxyV2() etcdmain/etcd.go
|-newConfig()
|-setupLogging()
|-startEtcd()
// 为客户端/服务器通信启动etcd服务器和HTTP处理程序。
| |-embed.StartEtcd() embed/etcd.go
| |-configurePeerListeners()
| |-configureClientListeners()
| |-EtcdServer.ServerConfig() 生成新的配置
| |-EtcdServer.NewServer() etcdserver/server.go正式启动RAFT服务<<<1>>>
| |-EtcdServer.Start() 开始启动服务
| | |-EtcdServer.start() 执行服务器开始服务请求所需的任何初始化
| | |-wait.New() 新建WaitGroup组以及一些管道服务
| | |-EtcdServer.run() etcdserver/raft.go 启动应用层的处理协程<<<2>>>
| | | |-raft.start() 启动处理协程
| |-Etcd.servePeers() 启动集群内部通讯
| | |-etcdhttp.NewPeerHandler() 新建http.Handler来处理etcd中其他成员请求
| | |-srv.Serve() 配置http服务
| | |-e.errHandler(l.serve()) 启动集群间http协程,开始多路传输监听
| |-Etcd.serveClients() 启动协程处理客户请求
| | |-http.NewServeMux() 启动监听客户端的协程
| | |-sctxs.serve() 启动服务器
| | |-v3rpc.Server() 启动gRPC服务 /etcdserver/api/v3rpc/grpc.go
| | | |-grpc.NewServer() 调用gRPC的接口创建
| | | |-pb.RegisterKVServer() 注册各种的服务,这里包含了多个
| | | |-pb.RegisterWatchServer()
| |-Etcd.serveMetrics()
|-notifySystemd()
|-select() 等待stopped
|-osutil.Exit()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
在标记 1 处会启动 RAFT 协议的核心部分,也就是node.run()[raft/node.go] 。
在标记 2 处启动的是 ETCD 应用层的处理协程,对应了 raftNode.start()[etcdserver/raft.go] 。
这里基本上是大致的启动流程,主要是解析参数,设置日志,启动监听端口等,接下来就是其核心部分 etcdserver.NewServer() 。
应用通过 raft.StartNode() 来启动 raft 中的一个副本,函数内部会通过启动一个 goroutine 运行。
//etcdserver/server.go
// NewServer creates a new EtcdServer from the supplied configuration. The
// configuration is considered static for the lifetime of the EtcdServer.
func NewServer(cfg config.ServerConfig) (srv *EtcdServer, err error) {
b, err := bootstrap(cfg)
//…
sstats := stats.NewServerStats(cfg.Name, b.cluster.cl.String())
lstats := stats.NewLeaderStats(cfg.Logger, b.cluster.nodeID.String())
heartbeat := time.Duration(cfg.TickMs) * time.Millisecond
srv = &EtcdServer{
…
r: *b.raft.newRaftNode(b.ss, b.storage.wal.w, b.cluster.cl),
…
}
serverID.With(prometheus.Labels{"server_id": b.cluster.nodeID.String()}).Set(1)
srv.cluster.SetVersionChangedNotifier(srv.clusterVersionChanged)
srv.applyV2 = NewApplierV2(cfg.Logger, srv.v2store, srv.cluster)
srv.be = b.storage.backend.be
srv.beHooks = b.storage.backend.beHooks
minTTL := time.Duration((3*cfg.ElectionTicks)/2) * heartbeat
// always recover lessor before kv. When we recover the mvcc.KV it will reattach keys to its leases.
// If we recover mvcc.KV first, it will attach the keys to the wrong lessor before it recovers.
srv.lessor = lease.NewLessor(…
})
tp, err := auth.NewTokenProvider(cfg.Logger, cfg.AuthToken,
func(index uint64) <-chan struct{} {
return srv.applyWait.Wait(index)
},
time.Duration(cfg.TokenTTL)*time.Second,
)
//…
mvccStoreConfig := mvcc.StoreConfig{
CompactionBatchLimit: cfg.CompactionBatchLimit,
CompactionSleepInterval: cfg.CompactionSleepInterval,
}
srv.kv = mvcc.New(srv.Logger(), srv.be, srv.lessor, mvccStoreConfig)
srv.corruptionChecker = newCorruptionChecker(cfg.Logger, srv, srv.kv.HashStorage())
srv.authStore = auth.NewAuthStore(srv.Logger(), schema.NewAuthBackend(srv.Logger(), srv.be), tp, int(cfg.BcryptCost))
newSrv := srv // since srv == nil in defer if srv is returned as nil
//…
if num := cfg.AutoCompactionRetention; num != 0 {
srv.compactor, err = v3compactor.New(cfg.Logger, cfg.AutoCompactionMode, num, srv.kv, srv)
if err != nil {
return nil, err
}
srv.compactor.Run()
}
if err = srv.restoreAlarms(); err != nil {
return nil, err
}
srv.uberApply = srv.NewUberApplier()
if srv.Cfg.EnableLeaseCheckpoint {
// setting checkpointer enables lease checkpoint feature.
srv.lessor.SetCheckpointer(func(ctx context.Context, cp *pb.LeaseCheckpointRequest) {
srv.raftRequestOnce(ctx, pb.InternalRaftRequest{LeaseCheckpoint: cp})
})
}
// Set the hook after EtcdServer finishes the initialization to avoid
// the hook being called during the initialization process.
srv.be.SetTxPostLockInsideApplyHook(srv.getTxPostLockInsideApplyHook())
// TODO: move transport initialization near the definition of remote
tr := &rafthttp.Transport{…
}
if err = tr.Start(); err != nil {
return nil, err
}
// add all remotes into transport
for _, m := range b.cluster.remotes {
if m.ID != b.cluster.nodeID {
tr.AddRemote(m.ID, m.PeerURLs)
}
}
for _, m := range b.cluster.cl.Members() {
if m.ID != b.cluster.nodeID {
tr.AddPeer(m.ID, m.PeerURLs)
}
}
srv.r.transport = tr
return srv, nil
}
// 函数调用关系链
NewServer() etcdserver/server.go 通过配置创建一个新的EtcdServer对象,不同场景不同
|-bootstrap(cfg)
| |-bootstrapSnapshot(cfg) 新建snap对象,等待存储或恢复
| |-wal.Exist()
| |-v2store.New() 初始化内存B+树
| |-bootstrapBackend() 初始化操作treeIndex以及BoltDB持久化的对象
| |-recoverSnapshot() 从快照中恢复
| |-bootstrapWALFromSnapshot() 已有WAL,在原有数据中恢复未提交数据
| |-bootstrapCluster() 对于每一个集群成员进行存储配置
| |-bootstrapStorage() 对于没有WAL情况,进行统一分配存储
| |-cluster.Finalize() 对于每一个集群成员进行最后配置
| |-bootstrapRaft() 为当前服务器配置raft 对象
|-stats.NewServerStats() 配置server状态
|-stats.NewLeaderStats() 成为Leader状态
|-srv=&EtcdServer{raft.newRaftNode() …}新建etcdserver对象,并初始化raft对象运行
| |-raft.RestartNode() 若无其他成员则重启节点
| |-raft.StartNode() 若有则新启节点
| |-setupNode() 配置节点
| | |-rn = NewRawNode() raft/node.go 新建一个type node struct对象
| | |-rn.Bootstrap(peers) 通过追加配置来初始化RawNode
| | |-raft.becomeFollower() 成为Follower状态
| | |-n := newNode(rn) 封装rawNode
| |-go node.run() 循环运行节点监听任务
|-lease.NewLessor() 恢复Lessor状态 mvcc.New
|- mvcc.New() 新建mvcc存储管理对象
|-auth.NewAuthStore()
raft.StartNode() <====会根据不同的启动场景执行相关任务
|-setupNode() 新建一个节点
| |-rn = NewRawNode() raft/node.go 新建一个type node struct对象
| |- rn.Bootstrap(peers) 通过追加配置来初始化RawNode
//这里会对关键对象初始化以及赋值,包括step=stepFollower r.tick=r.tickElection函数
| |-raft.becomeFollower()
| | |-raft.reset() 开始启动时设置term为1
| | |-raft.resetRandomizedElectionTimeout() 更新选举的随机超时时间
| |-raftLog.append() 将配置更新日志添加
|-node.run() raft/node.go 节点运行,会启动一个协程运行 <<<long running>>>
| |-node.rn.readyWithoutAccept()
| |-newReady() 新建type Ready对象
| |-raft.tick() 等待n.tickc管道,这里实际就是在上面赋值的tickElection()函数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
这里稍微提一下mvcc,mvcc是数据库中常见的一种并发控制的方式,即保存数据的多个版本,在同一个事务里,应用所见的版本是一致的。
在etcd中,mvcc底层使用 bolt 实现,bolt是一个基于B+树的KV存储。不同于以往认知,实际在存储过程中,Key是revision,而Value是用户给出的KV。为此,内存里维护了一个treeIndex的B+树,它存储了所有KV的所有版本记录。在查询数据时,先要通过内存btree在keyIndex.generations[0].revs中找到最后一条revision,即可去bbolt中读取对应的数据。相应的,etcd支持按key前缀查询,其实也就是遍历btree的同时根据revision去bbolt中获取用户的value。
与此同时,etcd封装了backend接口用来操作treeIndex以及BoltDB的持久化,使其能够从内存到磁盘BoltDB持久化流程。使用*bolt.DB来操作boltDB数据库。这里不展开各个操作的细节。
# 3.4.2 gRPC 服务
与客户端gRPC服务相似,服务器 RPC 接口的定义在 etcdserver/etcdserverpb/rpc.proto 文件中,对应了 service KV 中的定义,而真正的启动对应了 api/v3rpc/grpc.go 中的实现。
以 KV 存储为例,其对应了 NewQuotaKVServer() 中的实现,这里实际上是封装了一层,用来检查是否有足够的空间。
quotaKVServer.Put() api/v3rpc/quota.go 首先检查是否满足需求
|-quotoAlarm.check() 检查
|-KVServer.Put() api/v3rpc/key.go 真正的处理请求
|-checkPutRequest() 校验请求参数是否合法
|-RaftKV.Put() etcdserver/v3_server.go 处理请求
|=EtcdServer.Put() 实际调用的是该函数
| |-raftRequest()
| |-raftRequestOnce()
| |-processInternalRaftRequestOnce() 真正开始处理请求
| |-context.WithTimeout() 创建超时的上下文信息
| |-raftNode.Propose() raft/node.go
| |-raftNode.step() 对于类型为MsgProp类型消息,向propc通道中传入数据
|-header.fill() etcdserver/api/v3rpc/header.go填充响应的头部信息
2
3
4
5
6
7
8
9
10
11
12
13
14
# 3.4.3 处理流程
在运行处理数据过程中,etcd 服务端采用的是异步状态机,基于 GoLang 的 Channel 机制,RAFT 状态机作为一个 Background Thread/Routine 运行,会通过 Channel 接收上层传来的消息,状态机处理完成之后,再通过 Ready() 接口返回给上层。
其中 type Ready struct 结构体封装了一批更新操作,具体代码如下所示:
/ Ready encapsulates the entries and messages that are ready to read,
// be saved to stable storage, committed or sent to other peers.
// All fields in Ready are read-only.
type Ready struct {
*SoftState
pb.HardState
ReadStates []ReadState
Entries []pb.Entry
Snapshot pb.Snapshot
CommittedEntries []pb.Entry
Messages []pb.Message
MustSync bool
}
2
3
4
5
6
7
8
9
10
11
12
13
其中包括了:
(1) pb.HardState 需要在发送消息前持久化的消息,包含当前节点见过的最大的 term,在这个 term 给谁投过票,已经当前节点知道的 commit index;
(2) Messages 需要广播给所有 peers 的消息;
(3) CommittedEntries 已经提交但是还没有apply到状态机的日志;
(4) Snapshot 需要持久化的快照。
在 raft/node.go 中定义了 type node struct 对应的结构,一个 RAFT 结构通过 Node 表示各结点信息,该结构体内定义了各个管道,用于同步信息,下面会逐一遇到。
type node struct {
propc chan pb.Message
recvc chan pb.Message
confc chan pb.ConfChange
confstatec chan pb.ConfState
readyc chan Ready
advancec chan struct{}
tickc chan struct{}
done chan struct{}
stop chan struct{}
status chan chan Status
}
2
3
4
5
6
7
8
9
10
11
12
库的使用者从 type node struct 结构体提供的 ready channel 中不断 pop 出一个个 Ready 进行处理,库使用者通过如下方法拿到 Ready channel 。
// raft/node.go
func (n *node) Ready() <-chan Ready { return n.readyc }
2
应用需要对 Ready 的处理,在etcdserver/raft.go的start函数有明确指出,包括如下内容:
(1) 将 HardState、Entries、Snapshot 持久化到 storage;
(2) 将 Messages 非阻塞的广播给其他 peers;
(3) 将 CommittedEntries (已经提交但是还没有应用的日志) 应用到状态机;
(4) 如果发现 CommittedEntries 中有成员变更类型的 entry,则调用 node 的 ApplyConfChange() 方法让 node 知道;
(5) 调用 Node.Advance() 告诉 raft node 这批状态更新处理完,状态已经演进了,可以给我下一批 Ready 让我处理了。
# 3.5 Raft设计
# 3.5.1 概述
随着分布式技术的不断发展,单点故障场景下系统异常时有发生。为了解决单点问题,软件系统工程师引入了数据复制技术,实现多副本。而多副本间的数据复制就会出现一致性问题。所以需要共识算法来解决该问题。
共识算法(consensus algorithm)的祖师爷是 Paxos, 但是由于它过于复杂,难于理解,工程实践上也较难落地,导致在工程界落地较慢。 Raft 算法作为一种共识算法,正是为了可理解性、易实现而诞生的。
raft 会先选举出 leader,leader 完全负责 replicated log 的管理。leader 负责接受所有客户端更新请求,然后复制到 follower 节点,并在“安全”的时候执行这些请求。如果 leader 故障,followes 会重新选举出新的 leader。
通过 leader,raft 将一致性问题分解成三个相当独立的子问题:
Leader Election:当集群启动或者 leader 失效时必须选出一个新的leader。
Log Replication:leader 必须接收客户端提交的日志,并将其复制到集群中的其他节点,强制其他节点的日志与 leader 一样。
Safety:最关键的安全点就状态机安全属性(State Machine Safety Property)。如果任何一个 server 已经在它的状态机apply了一条日志,其他的 server 不可能在相同的 index 处 apply 其他不同的日志条目。在Log Replication的实现中有具体体现,就不单独赘述。
后面将会详细的讲述具体如何实现。
# 3.5.2 领导选举
在 RAFT 协议实现的代码中,node[raft/node.go] 是其核心的实现,也是整个分布式算法的核心所在。首先在 Raft 协议中它定义了集群中的如下节点状态,任何时刻,每个节点肯定处于其中一个状态:
(1) Follower,跟随者, 同步从 Leader 收到的日志,etcd 启动的时候默认为此状态;
(2) Candidate,竞选者,可以发起 Leader 选举;
(3) Leader,集群领导者, 唯一性,拥有同步日志的特权,需定时广播心跳给 Follower 节点,以维持领导者身份。
Raft 协议将时间划分成一个个任期(Term),任期用连续的整数表示,每个任期从一次选举开始,赢得选举的节点在该任期内充当 Leader 的职责,随着时间的消逝,集群可能会发生新的选举,任期号也会单调递增。通过任期号,可以比较各个节点的数据新旧、识别过期的 Leader 等,它在 Raft 算法中充当逻辑时钟,发挥着重要作用。
另外,通过 raftNode[etcdserver/raft.go] 对 node 进一步封装,只对 EtcdServer 暴露了 startNode()、start()、apply()、processMessages() 等少数几个接口。就如3.4.3处理流程提到的,其中核心部分是通过 start() 方法启动的一个协程,这里会等待从 readyc 通道上报的数据。
// etcdserver/raft.go
// start prepares and starts raftNode in a new goroutine. It is no longer safe
// to modify the fields after it has been started.
func (r *raftNode) start(rh *raftReadyHandler) {
internalTimeout := time.Second
go func() {
defer r.onStop()
islead := false
for {
select {
case <-r.ticker.C:
r.tick()
case rd := <-r.Ready():
if rd.SoftState != nil {
//申请Leader
newLeader := rd.SoftState.Lead != raft.None && rh.getLead() != rd.SoftState.Lead
if newLeader {
leaderChanges.Inc()
}
if rd.SoftState.Lead == raft.None {
hasLeader.Set(0)
} else {
hasLeader.Set(1)
}
rh.updateLead(rd.SoftState.Lead)
islead = rd.RaftState == raft.StateLeader
if islead {
isLeader.Set(1)
} else {
isLeader.Set(0)
}
rh.updateLeadership(newLeader)
r.td.Reset()
}
if len(rd.ReadStates) != 0 {
select {
case r.readStateC <- rd.ReadStates[len(rd.ReadStates)-1]:
case <-time.After(internalTimeout):
r.lg.Warn("timed out sending read state", zap.Duration("timeout", internalTimeout))
case <-r.stopped:
return
}
}
notifyc := make(chan struct{}, 1)
ap := toApply{
entries: rd.CommittedEntries,
snapshot: rd.Snapshot,
notifyc: notifyc,
}
updateCommittedIndex(&ap, rh)
select {
case r.applyc <- ap:
case <-r.stopped:
return
}
// the leader can write to its disk in parallel with replicating to the followers and them
// writing to their disks.
// For more details, check raft thesis 10.2.1
if islead {
// gofail: var raftBeforeLeaderSend struct{}
r.transport.Send(r.processMessages(rd.Messages))
}
// Must save the snapshot file and WAL snapshot entry before saving any other entries or hardstate to
// ensure that recovery after a snapshot restore is possible.
if !raft.IsEmptySnap(rd.Snapshot) {
// gofail: var raftBeforeSaveSnap struct{}
if err := r.storage.SaveSnap(rd.Snapshot); err != nil {
r.lg.Fatal("failed to save Raft snapshot", zap.Error(err))
}
// gofail: var raftAfterSaveSnap struct{}
}
// gofail: var raftBeforeSave struct{}
if err := r.storage.Save(rd.HardState, rd.Entries); err != nil {
r.lg.Fatal("failed to save Raft hard state and entries", zap.Error(err))
}
if !raft.IsEmptyHardState(rd.HardState) {
proposalsCommitted.Set(float64(rd.HardState.Commit))
}
// gofail: var raftAfterSave struct{}
if !raft.IsEmptySnap(rd.Snapshot) {
// Force WAL to fsync its hard state before Release() releases
// old data from the WAL. Otherwise could get an error like:
// panic: tocommit(107) is out of range [lastIndex(84)]. Was the raft log corrupted, truncated, or lost?
// See https://github.com/etcd-io/etcd/issues/10219 for more details.
if err := r.storage.Sync(); err != nil {
r.lg.Fatal("failed to sync Raft snapshot", zap.Error(err))
}
// etcdserver now claim the snapshot has been persisted onto the disk
notifyc <- struct{}{}
// gofail: var raftBeforeApplySnap struct{}
r.raftStorage.ApplySnapshot(rd.Snapshot)
r.lg.Info("applied incoming Raft snapshot", zap.Uint64("snapshot-index", rd.Snapshot.Metadata.Index))
// gofail: var raftAfterApplySnap struct{}
if err := r.storage.Release(rd.Snapshot); err != nil {
r.lg.Fatal("failed to release Raft wal", zap.Error(err))
}
// gofail: var raftAfterWALRelease struct{}
}
r.raftStorage.Append(rd.Entries)
if !islead {
// finish processing incoming messages before we signal raftdone chan
msgs := r.processMessages(rd.Messages)
// now unblocks 'applyAll' that waits on Raft log disk writes before triggering snapshots
notifyc <- struct{}{}
// Candidate or follower needs to wait for all pending configuration
// changes to be applied before sending messages.
// Otherwise we might incorrectly count votes (e.g. votes from removed members).
// Also slow machine's follower raft-layer could proceed to become the leader
// on its own single-node cluster, before toApply-layer applies the config change.
// We simply wait for ALL pending entries to be applied for now.
// We might improve this later on if it causes unnecessary long blocking issues.
waitApply := false
for _, ent := range rd.CommittedEntries {
if ent.Type == raftpb.EntryConfChange {
waitApply = true
break
}
}
if waitApply {
// blocks until 'applyAll' calls 'applyWait.Trigger'
// to be in sync with scheduled config-change job
// (assume notifyc has cap of 1)
select {
case notifyc <- struct{}{}:
case <-r.stopped:
return
}
}
// gofail: var raftBeforeFollowerSend struct{}
r.transport.Send(msgs)
} else {
// leader already processed 'MsgSnap' and signaled
notifyc <- struct{}{}
}
r.Advance()
case <-r.stopped:
return
}
}
}()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
接下来,我们再回过头来看一下3.4.3小节提到的后台启动程序node.run(),具体代码如下:
// raft/node.go
func (n *node) run() {
...
for {
...
select {
case pm := <-propc:
...
r.Step(m)
case m := <-n.recvc:
...
r.Step(m)
case cc := <-n.confc:
...
case <-n.tickc:
n.rn.Tick()
case readyc <- rd:
n.rn.acceptReady(rd)
advancec = n.advancec
case <-advancec:
n.rn.Advance(rd)
rd = Ready{}
advancec = nil
case c := <-n.status:
c <- getStatus(r)
case <-n.stop:
close(n.done)
return
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
主要是通过for-select-channel监听channel信息,来处理不同的请求。下面来看下几个主要的channel信息
propc和recvc中拿到的是从上层应用传进来的消息,这个消息会被交给raft层的Step函数处理。Step是etcd-raft模块负责各类信息的入口,其中default后面的step,被实现为一个状态机,它的step属性是一个函数指针,根据当前节点的不同角色,指向不同的消息处理函数:stepLeader/stepFollower/stepCandidate。与它类似的还有一个tick函数指针,根据角色的不同,也会在tickHeartbeat和tickElection之间来回切换,分别用来触发定时心跳和选举检测。
func (r *raft) Step(m pb.Message) error {
//...
switch m.Type {
case pb.MsgHup:
//...
case pb.MsgVote, pb.MsgPreVote:
//...
default:
r.step(r, m)
}
}
2
3
4
5
6
7
8
9
10
11
(1) 作为leader
当一个节点成为leader的时候,会将节点的定时器设置为tickHeartbeat,然后周期性的调用,维持leader的地位。
// raft/raft.go
func (r *raft) becomeLeader() {
// 检测当 前节点的状态,禁止从 follower 状态切换成 leader 状态
if r.state == StateFollower {
panic("invalid transition [follower -> leader]")
}
// 将step 字段设置成 stepLeader
r.step = stepLeader
r.reset(r.Term)
// 设置心跳的函数
r.tick = r.tickHeartbeat
// 设置lead的id值
r.lead = r.id
// 更新当前的角色
r.state = StateLeader
...
}
// raft/raft.go
func (r *raft) tickHeartbeat() {
// 递增心跳计数器
r.heartbeatElapsed++
// 递增选举计数器
r.electionElapsed++
...
if r.electionElapsed >= r.electionTimeout {
r.electionElapsed = 0
// 检测当前节点时候大多数节点保持连通
if r.checkQuorum {
r.Step(pb.Message{From: r.id, Type: pb.MsgCheckQuorum})
}
// If current leader cannot transfer leadership in electionTimeout, it becomes leader again.
if r.state == StateLeader && r.leadTransferee != None {
r.abortLeaderTransfer()
}
}
if r.heartbeatElapsed >= r.heartbeatTimeout {
r.heartbeatElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgBeat})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
becomeLeader中的step被设置成stepLeader,所以将会调用stepLeader来处理leader中对应的消息,并通过调用raft.bcastHeartbeat()向所有的节点发送心跳。
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
case pb.MsgBeat:
// 向所有节点发送心跳
r.bcastHeartbeat()
return nil
case pb.MsgCheckQuorum:
// 检测是否和大部分节点保持连通
// 如果不连通切换到follower状态
if !r.prs.QuorumActive() {
r.logger.Warningf("%x stepped down to follower since quorum is not active", r.id)
r.becomeFollower(r.Term, None)
}
return nil
...
}
}
// bcastHeartbeat sends RPC, without entries to all the peers.
func (r *raft) bcastHeartbeat() {
lastCtx := r.readOnly.lastPendingRequestCtx()
// 这两个函数最终都将调用sendHeartbeat
if len(lastCtx) == 0 {
r.bcastHeartbeatWithCtx(nil)
} else {
r.bcastHeartbeatWithCtx([]byte(lastCtx))
}
}
// 向指定的节点发送信息
func (r *raft) sendHeartbeat(to uint64, ctx []byte) {
commit := min(r.prs.Progress[to].Match, r.raftLog.committed)
m := pb.Message{
To: to,
// 发送MsgHeartbeat类型的数据
Type: pb.MsgHeartbeat,
Commit: commit,
Context: ctx,
}
r.send(m)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
最终的心跳通过MsgHeartbeat的消息类型进行发送,通知它们目前Leader的存活状态,重置所有Follower持有的超时计时器
(2) 作为follower
在step函数中将实现如下功能:接收到来自leader的RPC消息MsgHeartbeat,然后重置当前节点的选举超时时间,回复leader自己的存活。
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgProp:
...
case pb.MsgHeartbeat:
r.electionElapsed = 0
r.lead = m.From
r.handleHeartbeat(m)
...
}
return nil
}
func (r *raft) handleHeartbeat(m pb.Message) {
r.raftLog.commitTo(m.Commit)
r.send(pb.Message{To: m.From, Type: pb.MsgHeartbeatResp, Context: m.Context})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
(3) 作为Candidate
candidate来处理MsgHeartbeat的信息,是先把自己变成follower,然后和上面的follower一样,回复leader自己的存活。
func stepCandidate(r *raft, m pb.Message) error {
...
switch m.Type {
...
case pb.MsgHeartbeat:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleHeartbeat(m)
}
...
return nil
}
func (r *raft) handleHeartbeat(m pb.Message) {
r.raftLog.commitTo(m.Commit)
r.send(pb.Message{To: m.From, Type: pb.MsgHeartbeatResp, Context: m.Context})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
当leader收到返回的信息的时候,会将对应的节点设置为RecentActive,表示该节点目前存活。
func stepLeader(r *raft, m pb.Message) error {
...
// 根据from,取出当前的follower的Progress
pr := r.prs.Progress[m.From]
if pr == nil {
r.logger.Debugf("%x no progress available for %x", r.id, m.From)
return nil
}
switch m.Type {
case pb.MsgHeartbeatResp:
pr.RecentActive = true
...
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
当 Follower 节点接收 Leader 节点心跳消息超时后,它会转变成 Candidate 节点,并可发起新一轮的竞选 Leader 投票,若获得集群多数节点的支持后,它就可转变成 Leader 节点。
在Step函数中,我们可以看到MsgHup这个消息后会调用campaign函数,进入竞选状态。
// raft/raft.go
func (r *raft) Step(m pb.Message) error {
//...
switch m.Type {
case pb.MsgHup:
if r.preVote {
r.hup(campaignPreElection)
} else {
r.hup(campaignElection)
}
}
}
func (r *raft) hup(t CampaignType) {
...
r.campaign(t)
}
func (r *raft) campaign(t CampaignType) {
...
if t == campaignPreElection {
r.becomePreCandidate()
voteMsg = pb.MsgPreVote
// PreVote RPCs are sent for the next term before we've incremented r.Term.
term = r.Term + 1
} else {
// 切换到Candidate状态
r.becomeCandidate()
voteMsg = pb.MsgVote
term = r.Term
}
// 统计当前节点收到的选票 并统计其得票数是否超过半数,这次检测主要是为单节点设置的
// 判断是否是单节点
if _, _, res := r.poll(r.id, voteRespMsgType(voteMsg), true); res == quorum.VoteWon {
if t == campaignPreElection {
r.campaign(campaignElection)
} else {
// 是单节点直接,变成leader
r.becomeLeader()
}
return
}
...
// 向集群中的所有节点发送信息,请求投票
for _, id := range ids {
// 跳过自身的节点
if id == r.id {
continue
}
r.logger.Infof("%x [logterm: %d, index: %d] sent %s request to %x at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), voteMsg, id, r.Term)
var ctx []byte
if t == campaignTransfer {
ctx = []byte(t)
}
r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
竞选者切换到campaign状态,然后将自己的term信息发送出去,请求投票。这里,我们能看到对于Candidate会有一个PreCandidate,reCandidate这个状态的作用的是:
当系统曾出现分区,分区消失后恢复的时候,可能会造成某个被split的Follower的Term数值很大,对服务器进行分区时,它将不会收到heartbeat包,每次electionTimeout后成为Candidate都会递增Term,当服务器在一段时间后恢复连接时,Term的值将会变得很大,然后引入的重新选举会导致临时的延迟与可用性问题。而PreElection阶段并不会真正增加当前节点的Term,它的主要作用是得到当前集群能否成功选举出一个Leader的答案,避免上面这种情况的发生。
我们接着Candidate的状态来分析:对于能够投票的成员需要满足下面条件:
1、当前节点没有给任何节点投票或投票的节点term大于本节点的或者是之前已经投票的节点;
2、该节点的消息是最新的;
func (r *raft) Step(m pb.Message) error {
...
switch m.Type {
case pb.MsgVote, pb.MsgPreVote:
// We can vote if this is a repeat of a vote we've already cast...
canVote := r.Vote == m.From ||
// ...we haven't voted and we don't think there's a leader yet in this term...
(r.Vote == None && r.lead == None) ||
// ...or this is a PreVote for a future term...
(m.Type == pb.MsgPreVote && m.Term > r.Term)
// ...and we believe the candidate is up to date.
if canVote && r.raftLog.isUpToDate(m.Index, m.LogTerm) {
// 如果当前没有给任何节点投票(r.Vote == None)或者投票的节点term大于本节点的(m.Term > r.Term)
// 或者是之前已经投票的节点(r.Vote == m.From)
// 同时还满足该节点的消息是最新的(r.raftLog.isUpToDate(m.Index, m.LogTerm)),那么就接收这个节点的投票
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] cast %s for %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.Message{To: m.From, Term: m.Term, Type: voteRespMsgType(m.Type)})
if m.Type == pb.MsgVote {
// 保存下来给哪个节点投票了
r.electionElapsed = 0
r.Vote = m.From
}
} else {
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] rejected %s from %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.Message{To: m.From, Term: r.Term, Type: voteRespMsgType(m.Type), Reject: true})
}
...
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
然后,candidate节点接收到投票的信息,并统计投票的数量:
1、如果投票数大于节点数的一半的预置,成为leader;
2、如果达不到设定预置,变成follower;
func stepCandidate(r *raft, m pb.Message) error {
// Only handle vote responses corresponding to our candidacy (while in
// StateCandidate, we may get stale MsgPreVoteResp messages in this term from
// our pre-candidate state).
var myVoteRespType pb.MessageType
if r.state == StatePreCandidate {
myVoteRespType = pb.MsgPreVoteResp
} else {
myVoteRespType = pb.MsgVoteResp
}
switch m.Type {
case myVoteRespType:
// 计算当前集群中有多少节点给自己投了票
gr, rj, res := r.poll(m.From, m.Type, !m.Reject)
r.logger.Infof("%x has received %d %s votes and %d vote rejections", r.id, gr, m.Type, rj)
switch res {
// 大多数投票了
case quorum.VoteWon:
if r.state == StatePreCandidate {
r.campaign(campaignElection)
} else {
// 如果进行投票的节点数量正好是半数以上节点数量
r.becomeLeader()
// 向集群中其他节点广 MsgApp 消息
r.bcastAppend()
}
// 票数不够
case quorum.VoteLost:
// pb.MsgPreVoteResp contains future term of pre-candidate
// m.Term > r.Term; reuse r.Term
// 切换到follower
r.becomeFollower(r.Term, None)
}
...
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
每当收到一个MsgVoteResp类型的消息时,就会设置当前节点持有的votes数组,更新其中存储的节点投票状态,如果收到大多数的节点票数,切换成leader,向其他的节点发送当前节点当选的消息,通知其余节点更新Raft结构体中的Term等信息。
# 3.5.3 日志复制
在etcd中,所有数据的修改在提交前,都要先写入到WAL中。WAL(Write Ahead Log)是数据库中保证数据持久化的常用技术,即每次真正操作数据之前,先往磁盘上追加一条日志,由于日志是追加的,也就是顺序写,而不是随机写,所以写入性能还是很高的。这样做的目的是,记录了整个数据变化的全部历程
并且使用WAL进行数据的存储使得etcd拥有两个重要功能:
(1) 故障快速恢复: 当你的数据遭到破坏时,就可以通过执行所有WAL中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态。
(2) 数据回滚(undo)/重做(redo):因为所有的修改操作都被记录在WAL中,需要回滚或重做,只需要反向或正向执行日志中的操作即可。
在介绍Raft实现之前,我们先来简单概述一下WAL的基础使用。WAL对象定义如下:
// server/storage/wal/wal.go
// WAL这个抽象的结构体是由一堆的文件组成的
// 每个WAL文件的头部有一部分数据,是metadata,使用 w.Save 保存数据
// 使用完成之后,使用 w.Close 关闭
// WAL中的每一条记录,都有一个循环冗余校验码(CRC)
// WAL是只能打开来用于读,或者写,但是不能既读又写
type WAL struct {
lg *zap.Logger
dir string // the living directory of the underlay files
// dirFile is a fd for the wal directory for syncing on Rename
dirFile *os.File
metadata []byte // metadata recorded at the head of each WAL
state raftpb.HardState // hardstate recorded at the head of WAL
start walpb.Snapshot // snapshot to start reading
decoder *decoder // decoder to decode records
readClose func() error // closer for decode reader
unsafeNoSync bool // if set, do not fsync
mu sync.Mutex
enti uint64 // index of the last entry saved to the wal
encoder *encoder // encoder to encode records
locks []*fileutil.LockedFile // the locked files the WAL holds (the name is increasing)
fp *figolePipeline
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
在Save函数中,就是写入一条记录,然后调用 w.sync,而 w.sync 做的事情就是:调用了 fileutil.Fdatasync,而 fileutil.Fdatasync 就是调用了 fsync 这个系统调用保证数据会被写到磁盘。而快照也是类似的,写入一条记录,然后同步。
回归正题,在 RAFT 协议中,整个集群所有变更都必须通过 Leader 发起,如下其入口为 node.Propose (),而日志的保存总体流程如下:
(1) 集群某个节点收到client的put请求要求修改数据。节点会生成一个Type为MsgProp的Message,发送给leader。
// 生成MsgProp消息
func (n *node) Propose(ctx context.Context, data []byte) error {
return n.stepWait(ctx, pb.Message{Type: pb.MsgProp, Entries: []pb.Entry{{Data: data}}})
}
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgProp:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping proposal", r.id, r.Term)
return ErrProposalDropped
} else if r.disableProposalForwarding {
r.logger.Infof("%x not forwarding to leader %x at term %d; dropping proposal", r.id, r.lead, r.Term)
return ErrProposalDropped
}
// 设置发送的目标为leader
// 将信息发送给leader
m.To = r.lead
r.send(m)
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
(2) leader收到Message以后,会处理Message中的日志条目,将其append到raftLog的unstable的日志中,并且调用bcastAppend()广播append日志的消息。
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
...
case pb.MsgProp:
...
// 将Entry记录追加到当前节点的raftlog中
if !r.appendEntry(m.Entries...) {
return ErrProposalDropped
}
// 向其他节点复制Entry记录
r.bcastAppend()
return nil
...
}
return nil
}
func (r *raft) maybeSendAppend(to uint64, sendIfEmpty bool) bool {
pr := r.prs.Progress[to]
if pr.IsPaused() {
return false
}
m := pb.Message{}
m.To = to
...
m.Type = pb.MsgApp
m.Index = pr.Next - 1
m.LogTerm = term
m.Entries = ents
m.Commit = r.raftLog.committed
if n := len(m.Entries); n != 0 {
switch pr.State {
// optimistically increase the next when in StateReplicate
case tracker.StateReplicate:
last := m.Entries[n-1].Index
pr.OptimisticUpdate(last)
pr.Inflights.Add(last)
case tracker.StateProbe:
pr.ProbeSent = true
default:
r.logger.Panicf("%x is sending append in unhandled state %s", r.id, pr.State)
}
}
r.send(m)
return true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
(3) leader中的消息最终会以MsgApp类型的消息通知follower,follower收到这些信息之后,同leader一样,先将缓存中的日志条目持久化到磁盘中并将当前已经持久化的最新日志index返回给leader。
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgApp:
r.electionElapsed = 0
r.lead = m.From
r.handleAppendEntries(m)
}
return nil
}
func (r *raft) handleAppendEntries(m pb.Message) {
....
if mlastIndex, ok := r.raftLog.maybeAppend(m.Index, m.LogTerm, m.Commit, m.Entries...); ok {
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: mlastIndex})
}
...
}
// maybeAppend returns (0, false) if the entries cannot be appended. Otherwise,
// it returns (last index of new entries, true).
func (l *raftLog) maybeAppend(index, logTerm, committed uint64, ents ...pb.Entry) (lastnewi uint64, ok bool) {
...
l.commitTo(min(committed, lastnewi))
...
return 0, false
}
func (l *raftLog) commitTo(tocommit uint64) {
// never decrease commit
if l.committed < tocommit {
if l.lastIndex() < tocommit {
l.logger.Panicf("tocommit(%d) is out of range [lastIndex(%d)]. Was the raft log corrupted, truncated, or lost?", tocommit, l.lastIndex())
}
l.committed = tocommit
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
(4) 最后leader收到大多数的follower的确认,commit自己的log,同时再次广播通知follower自己已经提交了。
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
...
case pb.MsgAppResp:
pr.RecentActive = true
if r.maybeCommit() {
releasePendingReadIndexMessages(r)
// 如果可以commit日志,那么广播append消息
r.bcastAppend()
} else if oldPaused {
// 如果该节点之前状态是暂停,继续发送append消息给它
r.sendAppend(m.From)
}
...
}
return nil
}
// 尝试提交索引,如果已经提交返回true
// 然后应该调用bcastAppend通知所有的follower
func (r *raft) maybeCommit() bool {
mci := r.prs.Committed()
return r.raftLog.maybeCommit(mci, r.Term)
}
// 提交修改committed就可以了
func (l *raftLog) commitTo(tocommit uint64) {
// never decrease commit
if l.committed < tocommit {
if l.lastIndex() < tocommit {
l.logger.Panicf("tocommit(%d) is out of range [lastIndex(%d)]. Was the raft log corrupted, truncated, or lost?", tocommit, l.lastIndex())
}
l.committed = tocommit
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 四、总结与感悟
综上所述,etcd的源码分析分析在此告一段落,总的来说本次的源码分析过程对于我来说受益匪浅,通过现象看本质,从刚开始的功能介绍及应用场景为切入点,主要是回答了是什么和怎么用的话题,后续从组成模型及源码介绍出发,深入浅出的回答了为什么的话题。
每一个云原生开源项目的出现,都针对实实在在的问题与痛点,就如天上飞的理念,落地的实现,接口与实现类的关系。就我个人而言,起初从简单理解Raft算法过程,到如今慢慢理解Raft算法如何在真实场景的应用。虽然阅读源码很难,但我自己也渐渐积累了源码阅读的方法论,总的来说有提升也有所获。
源码不易,开源有意,希望我以这门课为起点,在后续的学习和开发过程中,积极参与到社区的大家庭中,贡献自己的一份力量。